
Hi! It's Run here! ツ
I am currently a second-year PhD student at RIT, advised by Prof. Dongfang Liu.
Research Interests: Efficient AI, Reinforcement Learning, LLMs, AI Agents
Personal email: runjia@msn.com (Preferred)
University email: rz4545@rit.edu / run@mail.rit.edu
Looking for a summer '26 internship!! 🙏
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Rochester Institute of TechnologyPh.D. Student in Electrical and Computer EngineeringAug. 2024 - present
Rochester Institute of TechnologyPh.D. Student in Electrical and Computer EngineeringAug. 2024 - present -
![Guangdong University of Technology <span style='color:#0070f8;'>[Honors Program]</span>](/assets/images/badges/Guangdong_University_of_Technology_Logo.svg.png) Guangdong University of Technology [Honors Program]B. Eng in Computer Science and TechnologySep. 2020 - May. 2024
Guangdong University of Technology [Honors Program]B. Eng in Computer Science and TechnologySep. 2020 - May. 2024
Experience
-
Institute of Software Chinese Academy of SciencesMachine Learning Engineer Intern on MindSpore (Chinese Huggingface 🤗) 900+ Stars, 500+ Issues, 1,700+ PRs.Apr. 2023 - Sep. 2023
Honors & Awards
-
National Scholarship Award, PRC2021
-
China Robot Competition & Robocup China Open National Champion2022
Academic Service
-
Reviewer: NeurIPS, TCSVT, MTA200+ papers reviewed
📂 Work in Progress
- First-author, Reinforcement Learning, Efficient Reasoning, Qwen
- First-author, AI Agents, GPT-OSS-20b, Qwen, Coding Agents, New Datasets
- First-author, Efficient Training, Qwen, Llama
News
Selected Publications (view all )

Probabilistic Token Alignment for Large Language Model Fusion
Runjia Zeng, James Chenhao Liang, Cheng Han, Zhiwen Cao, Jiahao Liu, Xiaojun Quan, Yingjie Victor Chen, Lifu Huang, Tong Geng, Qifan Wang, Dongfang Liu
NeurIPS Conference on Neural Information Processing Systems 2025
We introduce Probabilistic Token Alignment (PTA) for large language model fusion, reformulating token alignment as an optimal transport problem. PTA enhances performance and generality through distribution-aware learning while offering interpretability from a distributional perspective, which provides deeper insights into token alignment.
Probabilistic Token Alignment for Large Language Model Fusion
Runjia Zeng, James Chenhao Liang, Cheng Han, Zhiwen Cao, Jiahao Liu, Xiaojun Quan, Yingjie Victor Chen, Lifu Huang, Tong Geng, Qifan Wang, Dongfang Liu
NeurIPS Conference on Neural Information Processing Systems 2025
We introduce Probabilistic Token Alignment (PTA) for large language model fusion, reformulating token alignment as an optimal transport problem. PTA enhances performance and generality through distribution-aware learning while offering interpretability from a distributional perspective, which provides deeper insights into token alignment.
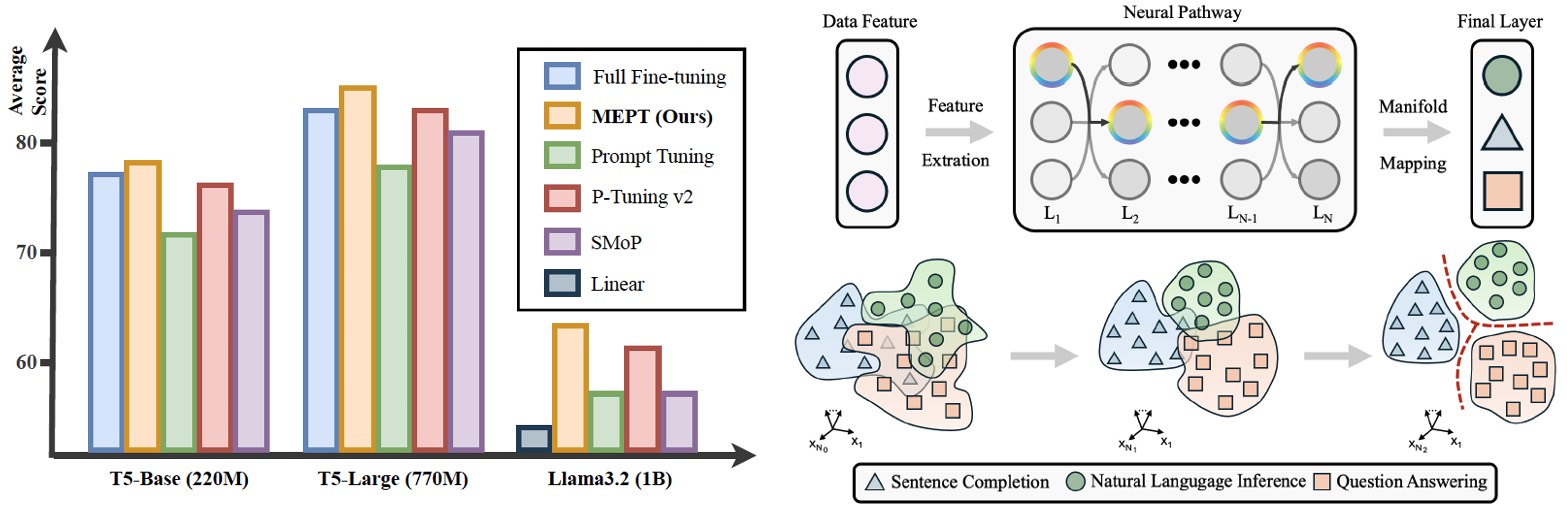
MEPT: Mixture of Experts Prompt Tuning as a Manifold Mapper
Runjia Zeng, Guangyan Sun, Qifan Wang, Tong Geng, Sohail Dianat, Xiaotian Han, Raghuveer Rao, Xueling Zhang, Cheng Han, Lifu Huang, Dongfang Liu
EMNLP Conference on Empirical Methods in Natural Language Processing 2025
Considering deep neural networks as manifold mappers, the pretrain-then-fine-tune paradigm is a two-stage process: pretrain builds a broad knowledge base, and fine-tune adjusts parameters to activate specific neural pathways aligning with the target manifold. The rigid parameter space constrain of prior prompt tuning methods limits dynamic pathway activation, making them less adaptable to diverse and evolving data. In this view, we propose Mixture of Expert Prompt Tuning (MEPT) that leverages multiple prompt experts to adaptively learn diverse and non-stationary data distributions.
MEPT: Mixture of Experts Prompt Tuning as a Manifold Mapper
Runjia Zeng, Guangyan Sun, Qifan Wang, Tong Geng, Sohail Dianat, Xiaotian Han, Raghuveer Rao, Xueling Zhang, Cheng Han, Lifu Huang, Dongfang Liu
EMNLP Conference on Empirical Methods in Natural Language Processing 2025
Considering deep neural networks as manifold mappers, the pretrain-then-fine-tune paradigm is a two-stage process: pretrain builds a broad knowledge base, and fine-tune adjusts parameters to activate specific neural pathways aligning with the target manifold. The rigid parameter space constrain of prior prompt tuning methods limits dynamic pathway activation, making them less adaptable to diverse and evolving data. In this view, we propose Mixture of Expert Prompt Tuning (MEPT) that leverages multiple prompt experts to adaptively learn diverse and non-stationary data distributions.
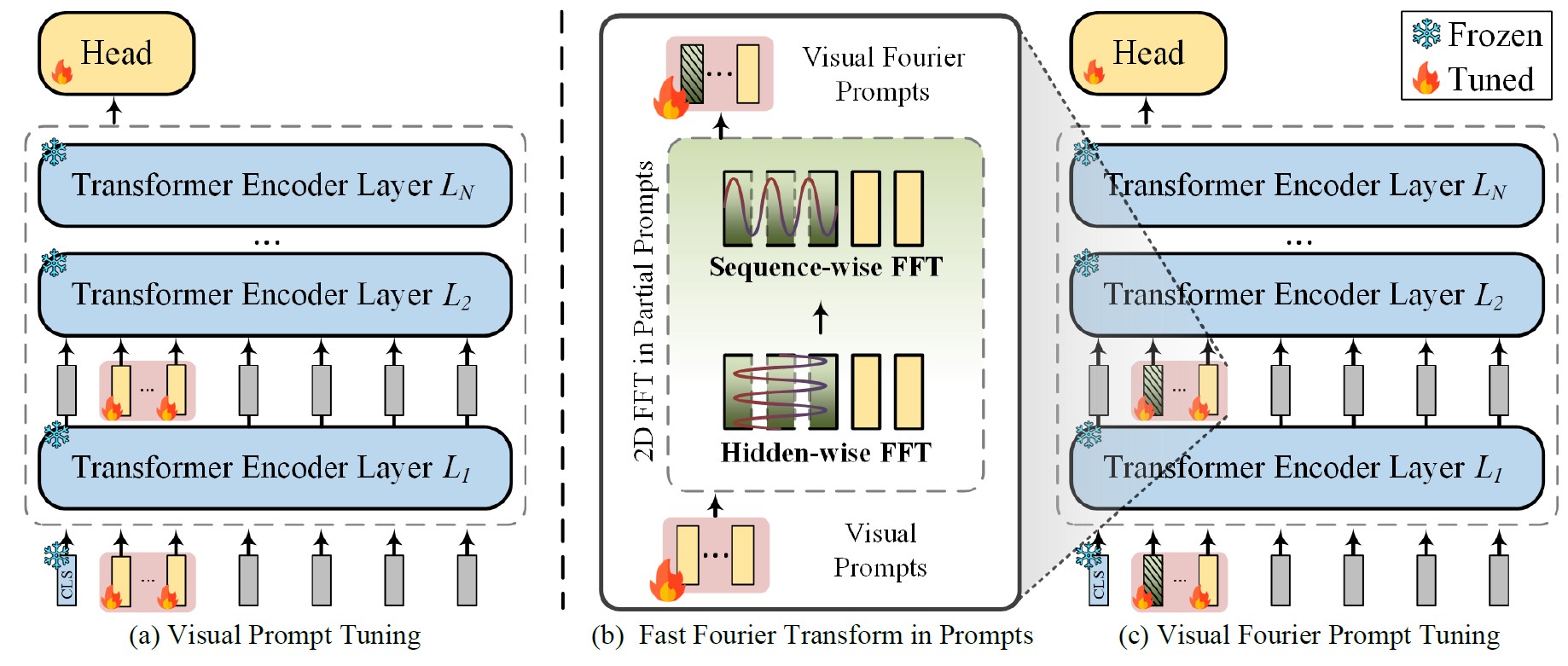
Visual Fourier Prompt Tuning
Runjia Zeng, Cheng Han, Qifan Wang, Chunshu Wu, Tong Geng, Lifu Huang, Ying Nian Wu, Dongfang Liu
NeurIPS Conference on Neural Information Processing Systems 2024
To tackle performance drops caused by data differences between pretraining and finetuning, we propose Visual Fourier Prompt Tuning (VFPT), which leverages the Fast Fourier Transform to combine spatial and frequency domain information, achieving better results with fewer parameters.
Visual Fourier Prompt Tuning
Runjia Zeng, Cheng Han, Qifan Wang, Chunshu Wu, Tong Geng, Lifu Huang, Ying Nian Wu, Dongfang Liu
NeurIPS Conference on Neural Information Processing Systems 2024
To tackle performance drops caused by data differences between pretraining and finetuning, we propose Visual Fourier Prompt Tuning (VFPT), which leverages the Fast Fourier Transform to combine spatial and frequency domain information, achieving better results with fewer parameters.
